Live Preview
Live
🚀
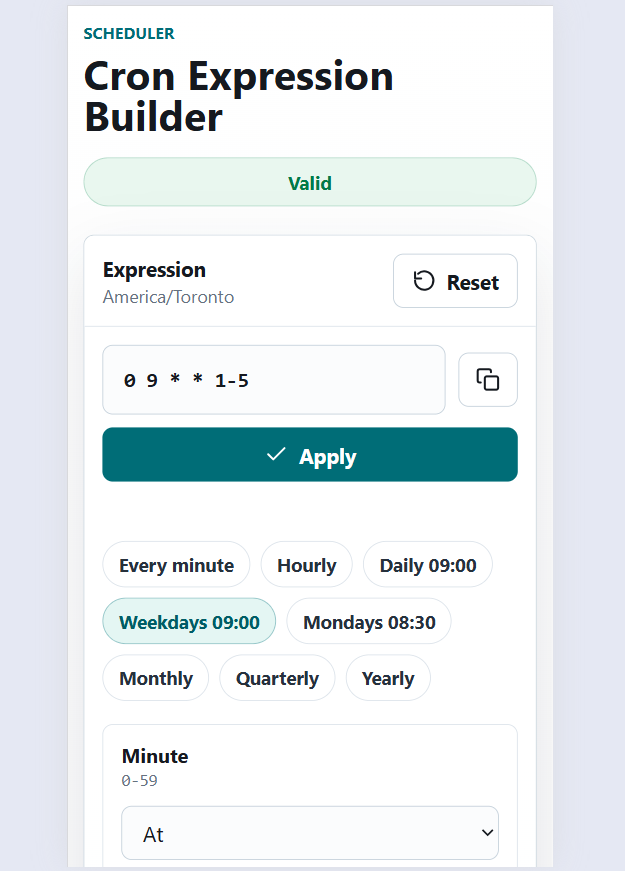
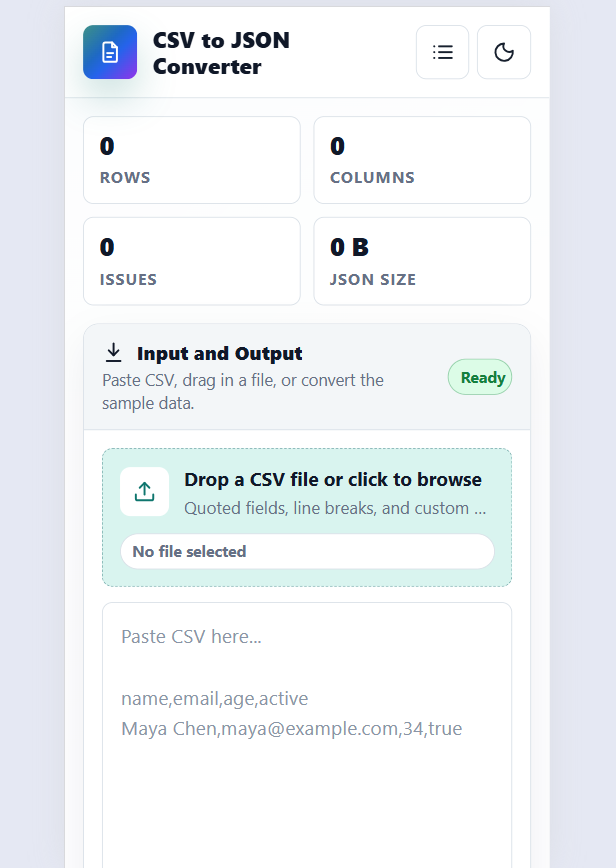
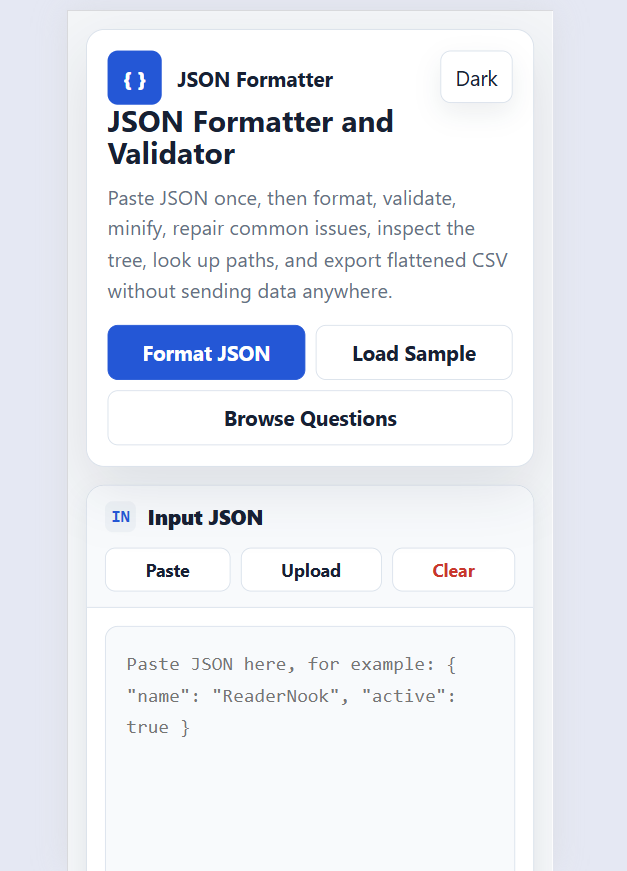
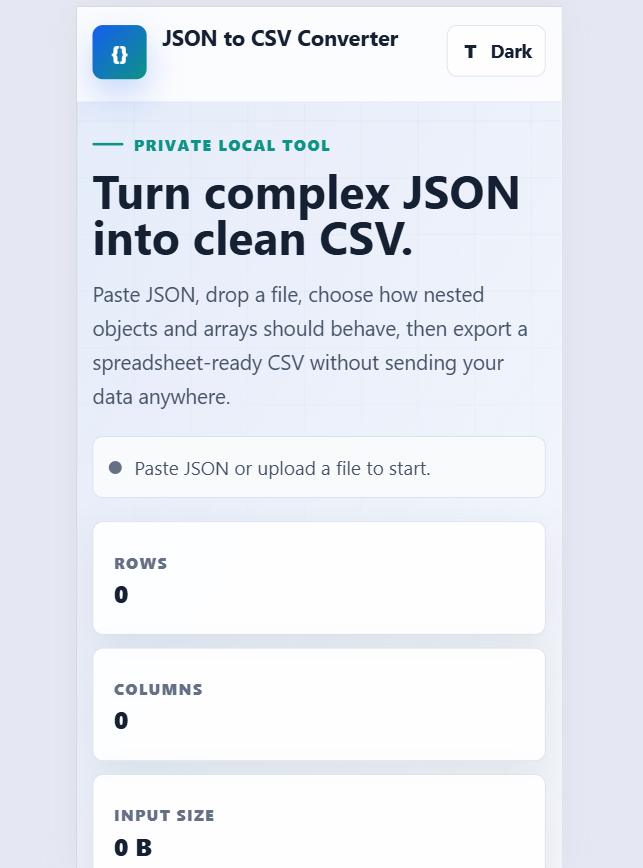
Git Command Helper
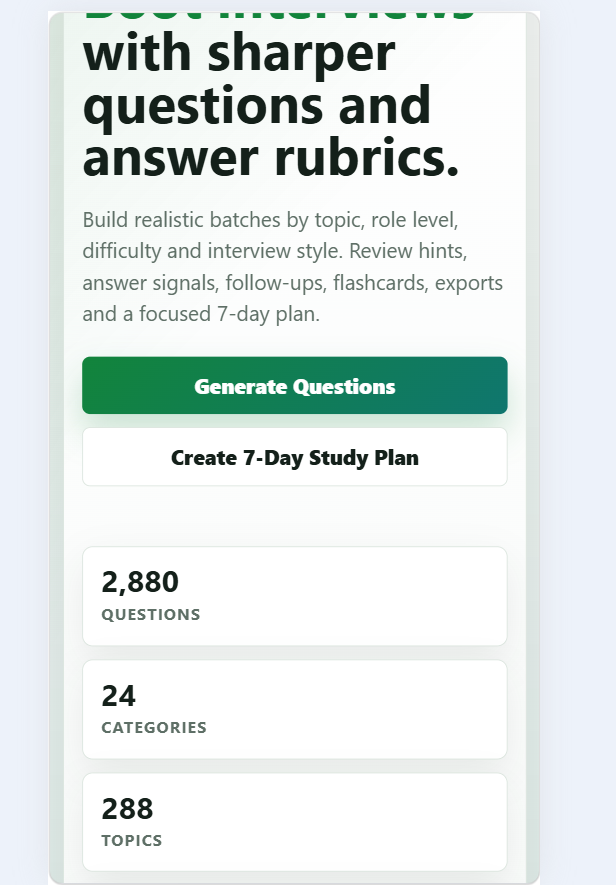
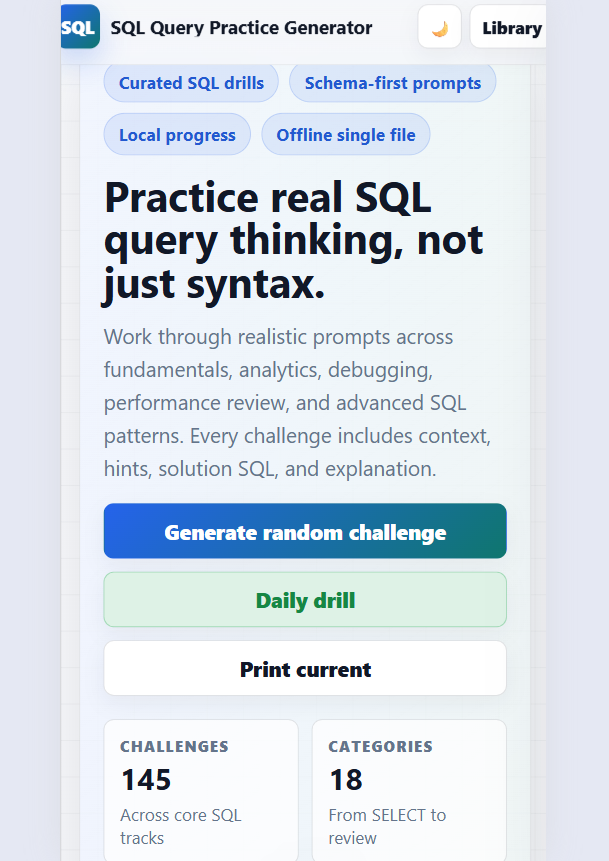
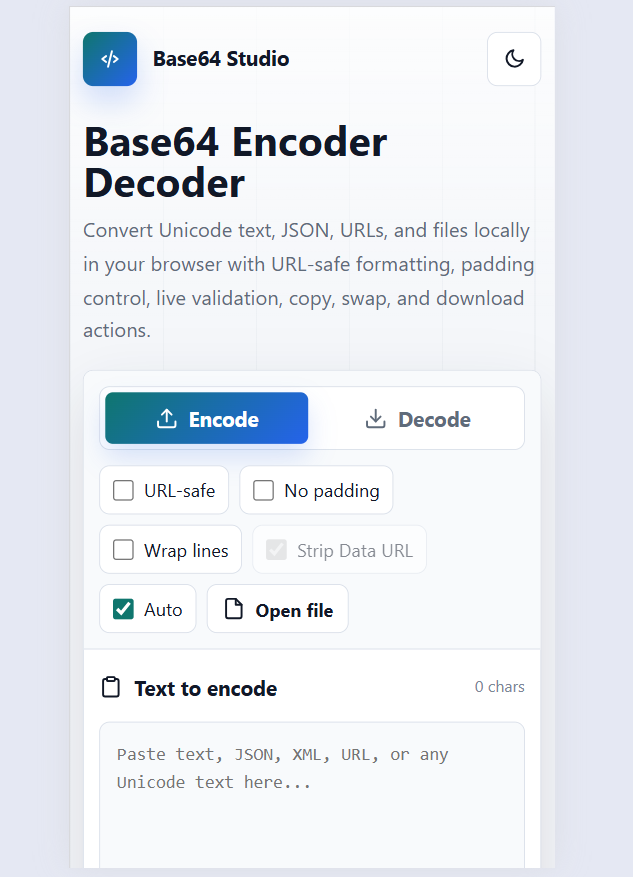
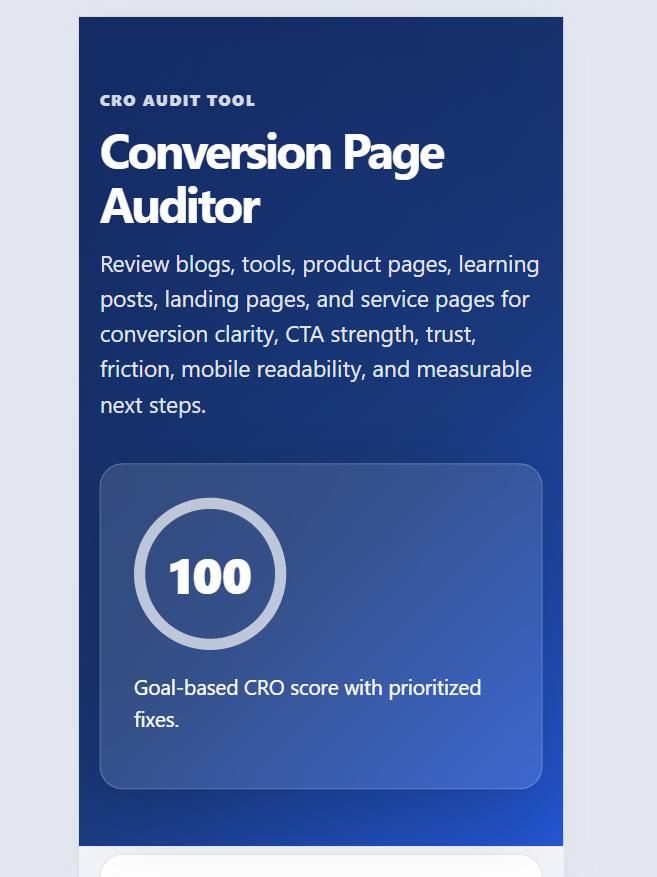
Find, build, and copy useful Git commands for branching, commits, stash, remotes, merge, rebase, undo actions, and daily developer workflows.
Itcodescanner · v1.0.0
Launch App